Introduction
Three years back, I looked into the field of Object reidentification as a way to answer the question of whether two vehicle views from two different cameras belong to same vehicle or different vehicle. As a beginner to this field, I found the re-identification pipeline to be quite complex compared to the standard computer vision usecases of supervised training of a model with a image-label pairs. This article introduces the fundamentals of ReID, providing a foundation for anyone interested in getting started in this domain.
What is Re-Identification?
Re-identification (ReID), is the task of recognizing the same object (typically a person/vehicle) across different conditions such as changes in camera viewpoints, lighting, or occlusion.
In practice, this means that once an object is assigned a unique ID, the system should consistently assign that same ID even if the object moves between different cameras. Designing a deep learning solution to this problem requires model to be able to create a hash solution that maps each person to a unique id, much like a hash method used in dictionary to reduce hash collisions.
1. Solving ReID as a Classification Problem
A straightforward way to approach ReID is to treat it as a classification task.
For example, suppose we want to design a ReID system that grants automatic access to authorized employees. We could train a classifier on a labeled dataset of employee images, where each person is treated as a separate class.
While valid, this approach has two major drawbacks:
- Retraining required for new identities: Each time a new employee joins, the entire model must be retrained to add their class.
- Scalability issues: As the number of classes (here classes are people) grows, the final classification layer becomes increasingly large, consuming more memory and compute. This makes training and inference inefficient.
These limitations make pure classification technique unsuitable for open-set ReID, where the number of identities is not fixed in advance.
2. Solving ReID as an Metric Learning Problem
The standard approach to ReID is to treat it as a metric learning problem rather than a classification problem. A unique metric learning is an ML technique that teaches models to measure the similarity or difference between data points, creating an embedding space where similar items are close together and dissimilar items are far apart. Instead of predicting discrete IDs, the model learns to map each person into a feature embedding space. This vector representing the given person is called its embedding.
The below diagram illustrates an ideal embedding space where embeddings of birds from same species are closer to each other.
For object re-identification, we create a model that generates embeddings such that:
- For images of the same object, the distance between their embeddings should be small.
- For images of different objects, the distance between their embeddings should be large.
We can now utilize this learned metric to check if two objects are same by checking if the distance between their embeddings are small enough.
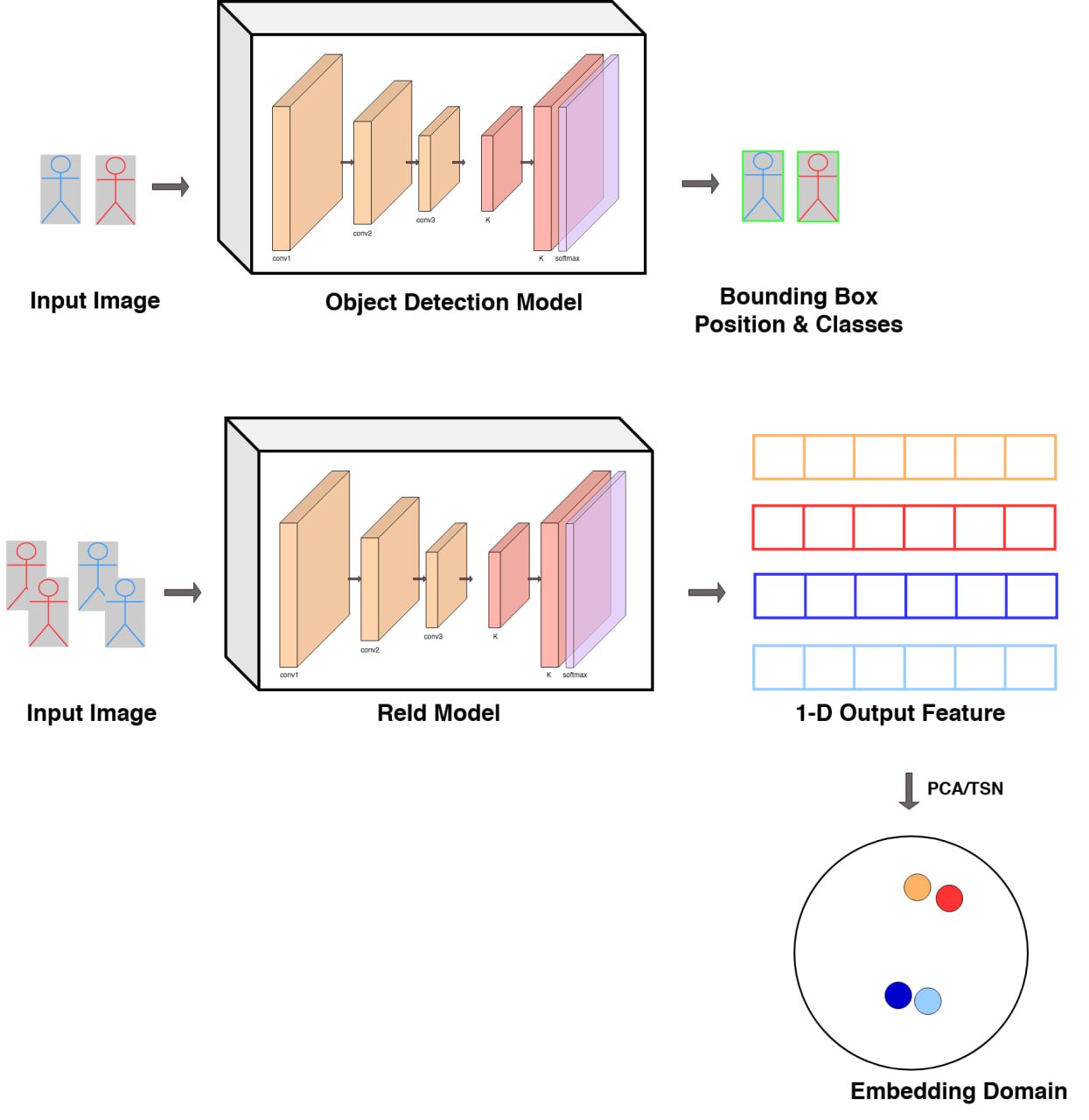
Designing ReID Pipeline
The foundation of a ReID model lies in learning a strong embedding function \(f\). This function maps an input image of a person to a feature vector, also called an appearance embedding.
Here’s how it works:
- The input is usually a cropped bounding box of a detected object (obtained from an object detector). This reduces the noise coming from background and ensures model focuses more on the object of interest.
- A ReID model processes this cropped image and outputs a high-dimensional feature vector (e.g., 512 or 1024 dimensions). This vector encodes the person’s visual appearance, acting as a unique signature.
- Similarity between two people is measured by comparing their embeddings, using distance metrics such as cosine or euclidean distance.
Formally, let \(f(x)\) denote the embedding of image \(x\). Given two images of the same person \(x_1\), \(x_2\) and an image of a different person \(y\), we want:
where \(\theta\) is usually a small distance threshold called margin (often 0.3) as depicted below. The below diagram depicts how embeddings of 2 parrots are good whereas embeddings of Ostrich 2 is bad being too close to the parrots cluster.
This embedding-based formulation makes ReID flexible and scalable: new objects can be matched without retraining, and the same system can handle thousands or even millions of identities.
Loss Functions in ReID
The key to training a good ReID model is ensuring that embeddings of the same object cluster closely, while embeddings of different objects remain well separated. To train such a model, 2 types of loss functions are commonly used, often together.
1. Contrastive Loss
Contrastive loss works on pairs of images. Given two images (\(p\), \(q\)) and a label y where:
- \(y=1\) if they belong to the same person,
- \(y=0\) otherwise.
Then, contrastive loss is defined as:
This encourages embeddings of the same person to be close together and embeddings of different people to be farther apart by at least a margin θ.
2. Classification (Softmax / Cross-Entropy) Loss
While ReID is an open-set problem (new identities appear during inference), adding a classification objective during training can significantly improve performance.
Here, each training identity is treated as a class, and the model is trained with softmax + cross-entropy loss:
where \(y_i\) is the ground-truth label and \(p_i\) is the predicted probability for class i.
This encourages the network to learn discriminative features for each identity, which strengthens the embedding space.
Important
At inference, the classification head is discarded, and only the embeddings are used for similarity matching.
3. Combined Loss
Modern ReID models often combine metric loss (contrastive, triplet, or variants) with classification loss:
where \(\lambda\) balances the two objectives. This joint training strategy has become a standard practice in state-of-the-art ReID systems.
Tip
There are over 20 types of losses, for e.g. circle loss, center loss and more. However, a combination of Contrastive loss and Classification loss is a good start.
Evaluation Metrics for ReID
ReID performance is not measured by classification accuracy but by how well embeddings retrieve the correct identity. The most common metrics are:
- Cumulative Matching Characteristic (CMC)
- Probability that the correct match appears within the top-k retrieved results.
- Rank-1 accuracy is especially popular.
- Mean Average Precision (mAP)
- Considers multiple ground-truth matches in the gallery.
- More comprehensive than CMC alone.
- Distance Distribution Plots
- Histograms of intra-class vs. inter-class distances provide insights into how well embeddings separate identities.
Standard Models for ReID
ReID models are typically built on strong image feature extractors. Common approaches include:
- Backbone CNNs
- ResNet-50: The standard baseline, pretrained on ImageNet.
- Zhou et al. (2019): A lightweight OS-Net model designed specifically for ReID, capturing features at multiple scales.
- Transformer-based Models
- He et al. (2021): TransReID was the first work in adapting Vision Transformers (ViTs) for ReID, using part-based attention to handle viewpoint variations.
- Li et al. (2023): Clip-ReID builds upon TransReID and adapts ReID training pipeline to finetune CLIP model by OpenAI with both images and text tokens for each person.
Data Sampling
START with Random Sampling and the fact that standard models use a single dataset sample independent of other samples.
Training a ReID model is not just about choosing the right architecture and loss function — the sampling strategy used to construct mini-batches is equally important. Since the model learns to compare embeddings, we must ensure that each batch contains meaningful positive (same person) and negative (different people) pairs.
Batch Construction
To enable effective metric learning, a typical batch is built using the following rules:
- At least two images per identity: This guarantees that positive pairs (same person) exist within the batch.
- At least two different identities per batch: This ensures the presence of negative pairs (different people).
In practice, datasets are often sampled using a P × K strategy:
- Select P identities at random.
- For each identity, randomly sample K images.
- This results in a batch size of P×K.
For example, with P=16 and K=4, each batch contains 64 images, covering 16 different people with 4 samples each.
Why This Matters
- Positive Pairs: Necessary for contrastive/triplet loss to learn tight intra-class clustering.
- Negative Pairs: Prevent embeddings of different people from collapsing together.
- Balanced Training: Ensures the model consistently sees diverse comparisons within each batch.
Beyond Pairwise Sampling
Advanced strategies include:
- Hard Negative Mining: Focuses on negatives that are visually similar but belong to different identities, which forces the model to learn more discriminative embeddings.
- Adaptive Sampling: Dynamically selects pairs or triplets based on current embedding distances to maintain effective training.
In the upcoming blogs, we will dive deeper into individual aspects of training a ReID model and build a strong baseline model step-by-step.
References
Shuting He, Hao Luo, Pichao Wang, Fan Wang, Hao Li, and Wei Jiang. Transreid: transformer-based object re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 15013–15022. October 2021. ↩
Siyuan Li, Li Sun, and Qingli Li. Clip-reid: exploiting vision-language model for image re-identification without concrete text labels. In Proceedings of the AAAI conference on artificial intelligence, volume 37, 1405–1413. 2023. ↩
Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, and Tao Xiang. Omni-scale feature learning for person re-identification. In ICCV. 2019. ↩
Discussion